

I Fed This Article Into Meta’s TRIBE v2
In Silico fMRI prediction. Simulate Brain Activity.

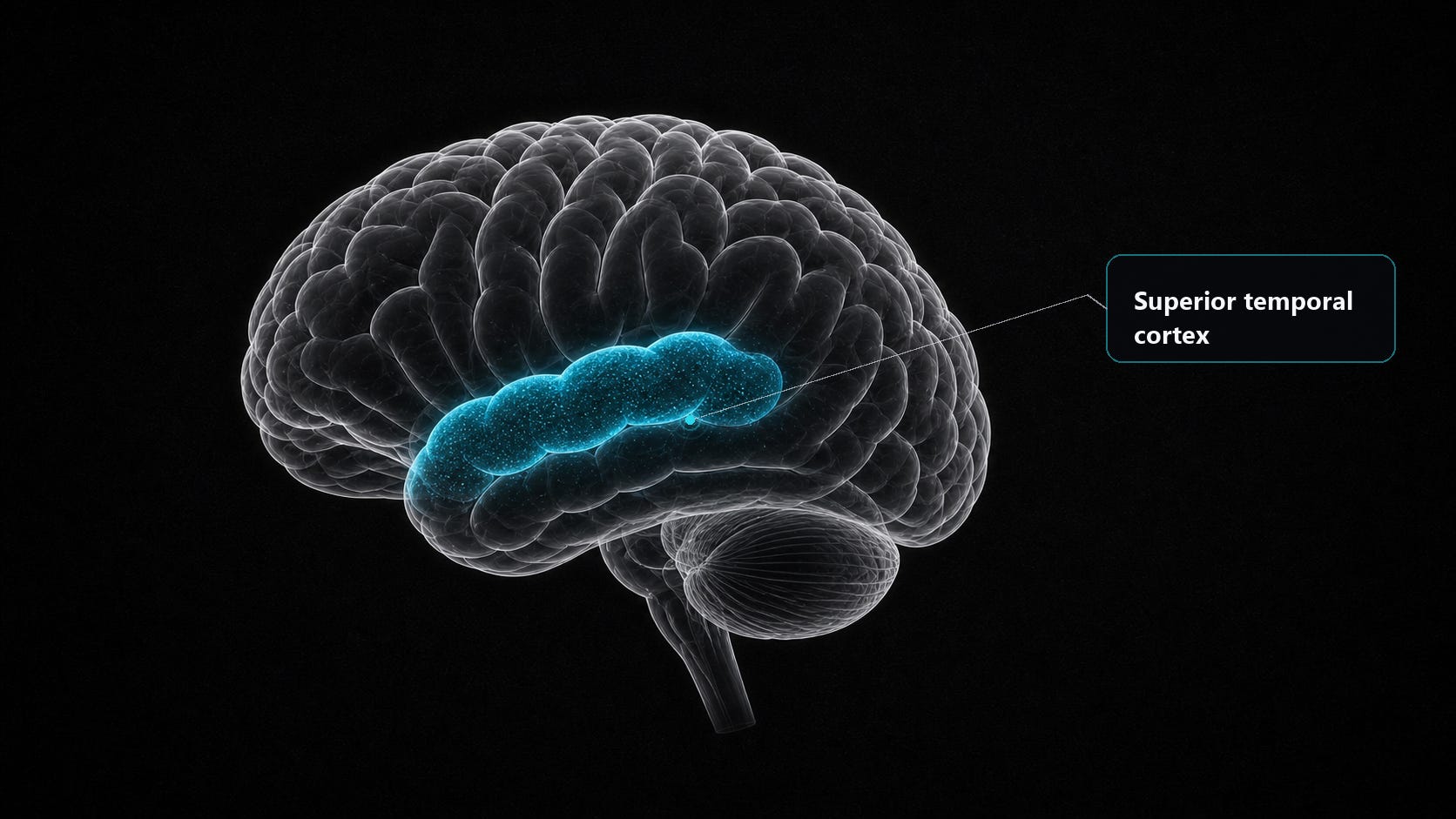
TRIBE v2 predicts this opening drives superior temporal cortex, the region of the brain that binds a running sequence of words into sentence-level meaning and pulls the core claim out of it.
Most writing feedback looks at the page.
TRIBE v2 looks at what the page does to a brain.
It is a model that predicts where in your brain lights up, and when, in response to media.
Not whether the writing is good. Not whether you will trust it or share it. Just: given this stimulus, what is the predicted pattern of neural response, second by second.
That is a different kind of mirror. One that shows what your draft is actually doing, not what you intended it to do.
So I ran the obvious experiment.
I wrote an article about TRIBE v2. Then I fed the article into TRIBE v2. Then I used the output as editorial feedback and rewrote from the prediction.
The article became the test subject.
What TRIBE v2 Is
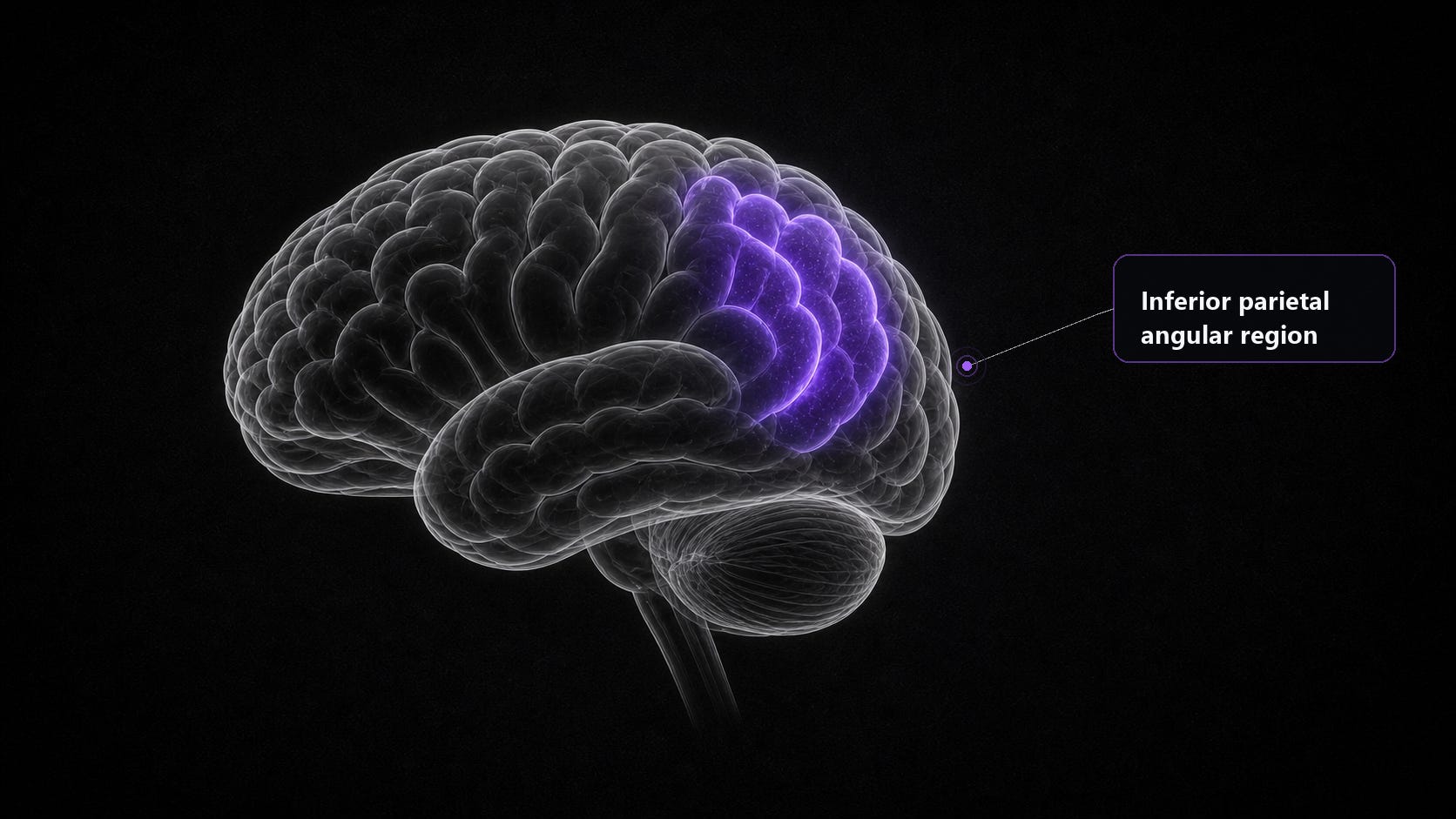
TRIBE v2’s strongest predicted region was here is the sulcus of Jensen and the surrounding inferior parietal cortex, where separate concepts get integrated and a new idea is mapped onto what you already know.
Meta announced TRIBE v2 in March 2026: a foundation model that predicts brain responses to video, audio, and text.
The paper reports it leveraging a unified dataset of over 1,000 hours of fMRI across 720 subjects, and shows it recovering results from decades of empirical neuroscience without running the experiments on people.
The simple way to understand it:
A chatbot predicts the next useful token.
TRIBE v2 predicts a pattern of brain activity in response to what you just showed it.
Two articles can contain identical facts. One makes you remember the point. One doesn’t. TRIBE v2 asks: which moments are doing the work?
That question turns a draft into something measurable.
Running The Experiment
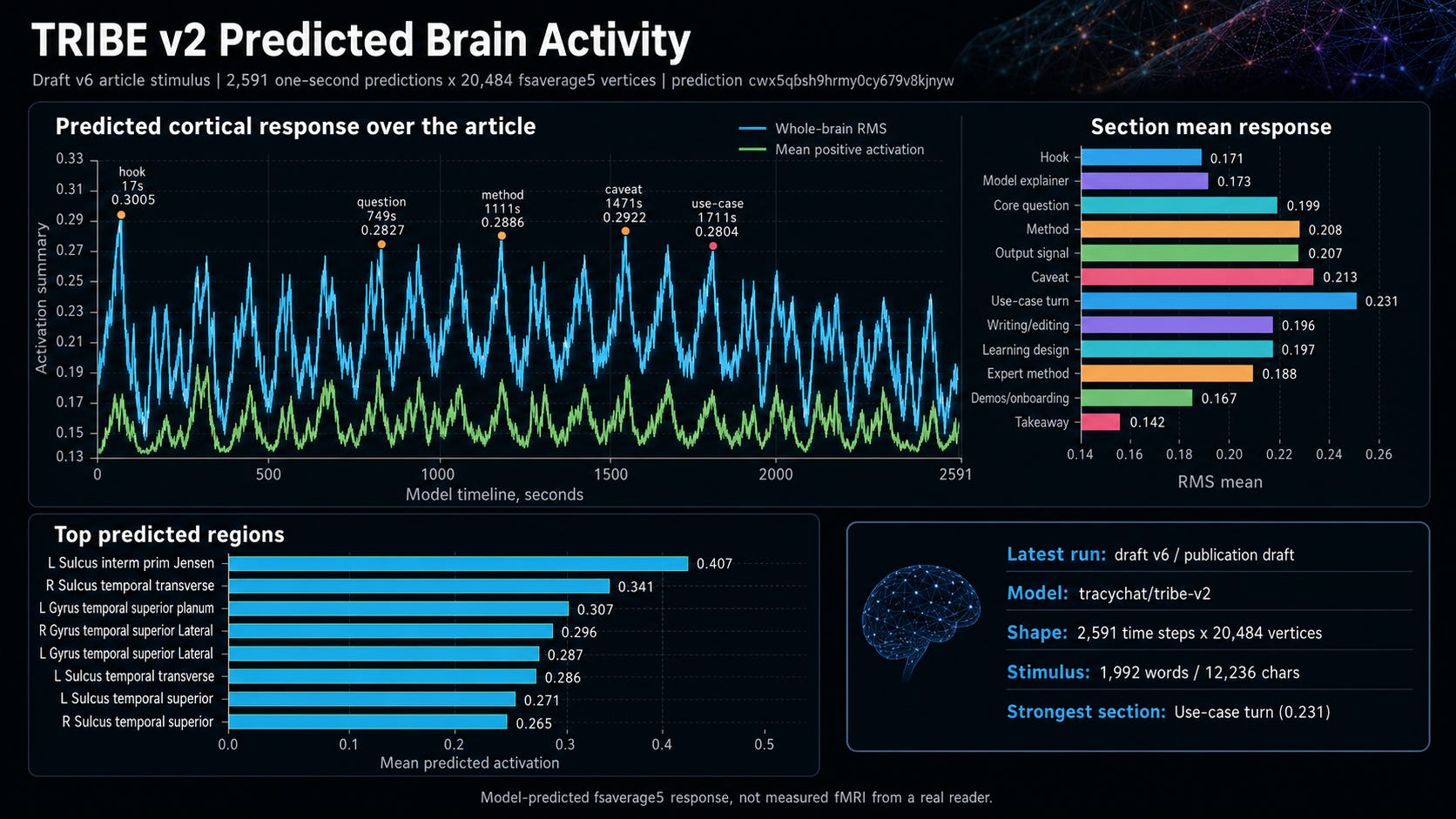
I converted the draft into a timed text stimulus, 1,992 words, 12,236 characters, and ran it through a deployment of TRIBE v2.
The model returned predicted cortical activity for every second of reading: 2,591 one-second steps across 20,484 surface points.
Then I mapped the response back onto the draft, section by section. It was not flattering, and that was the point:
The strongest section was the use-case turn , mean activation 0.231 , the moment the article stops explaining the model and starts showing what you’d do with it. The explaining was not the payload. The turn was.
The opening spikes hard at second 17 (0.3005) and then falls off a cliff. As a section, the hook averages only 0.171 and the model explainer 0.173, the two weakest stretches in the piece. A loud first sentence, then nothing holding it. The part I was proudest of was doing the least work.
A phrase I liked , “double meta” , sat in a low-signal trough. The model didn’t make me cut it; it just showed me it was decorative. The real sentence was simpler: the article became the test subject.
And the lowest section of all was the original ending: a mean of 0.142, well under everything else , below even the throwaway demos paragraph at 0.167. The model had flagged my own conclusion as the deadest part of the piece.
So I cut it. The section you’re reading now is the one I wrote from the output signal instead.
What The Output Is Actually Telling You
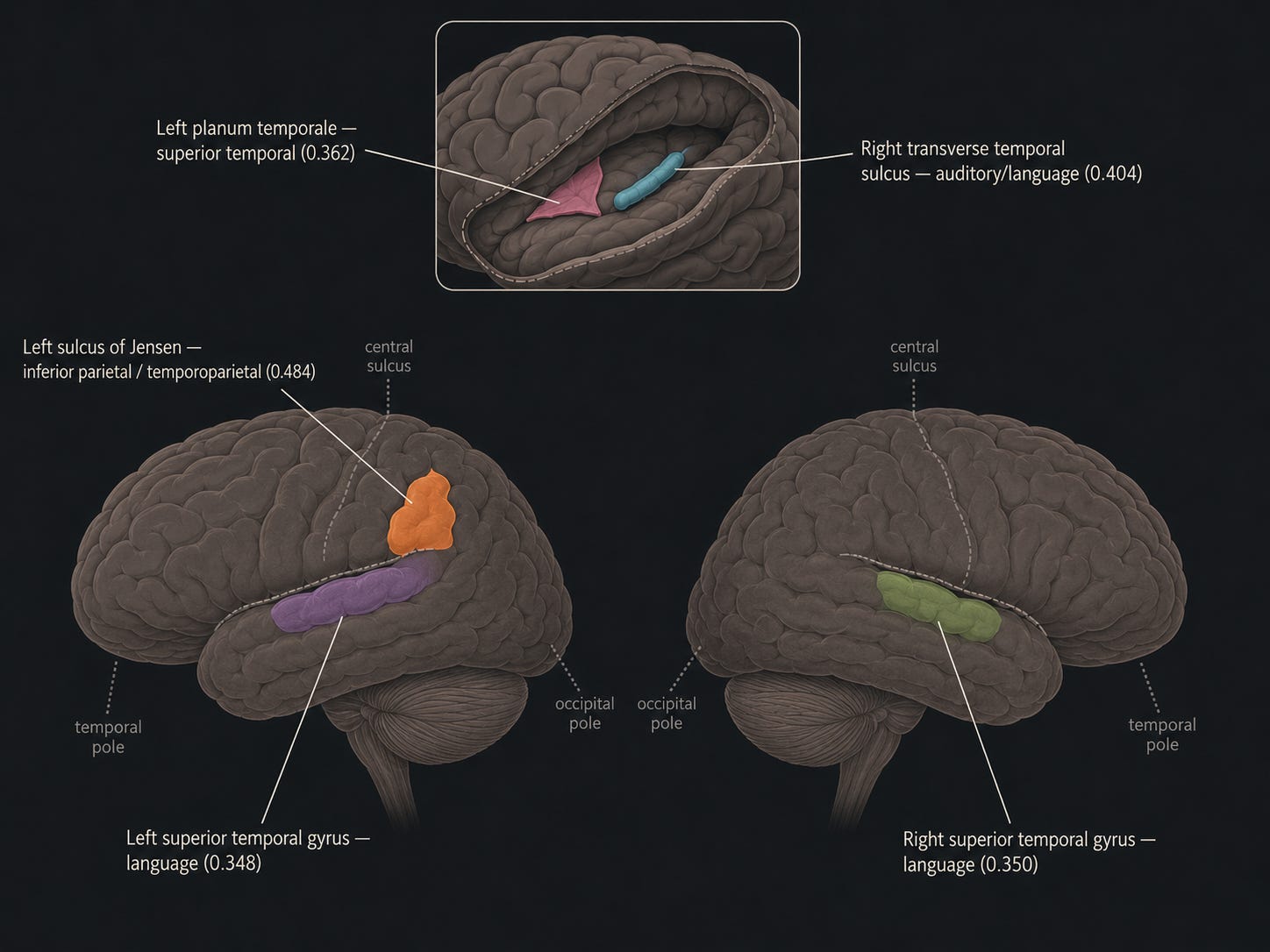
When this section lands, the brain reads it the way it reads language: inferior parietal cortex pulling separate ideas into one, and superior temporal cortex turning a stream of words into meaning. The deeper auditory-language structures, buried in the fold, are shown opened out in the inset.
Think of it as a spell-checker for emphasis, not spelling.
It cannot tell you if the article is true, persuasive, or worth reading. What it can tell you is whether the moments you intended to land are the moments carrying the load - or whether something incidental is doing more work than the point you actually care about.
TRIBE v2-style feedback surfaces that problem before the article goes out. It lets you ask: does the structure make the right thing central? If version A opens with the research and version B opens with the experiment, are they producing different response patterns around the moment that matters?
Takeaway
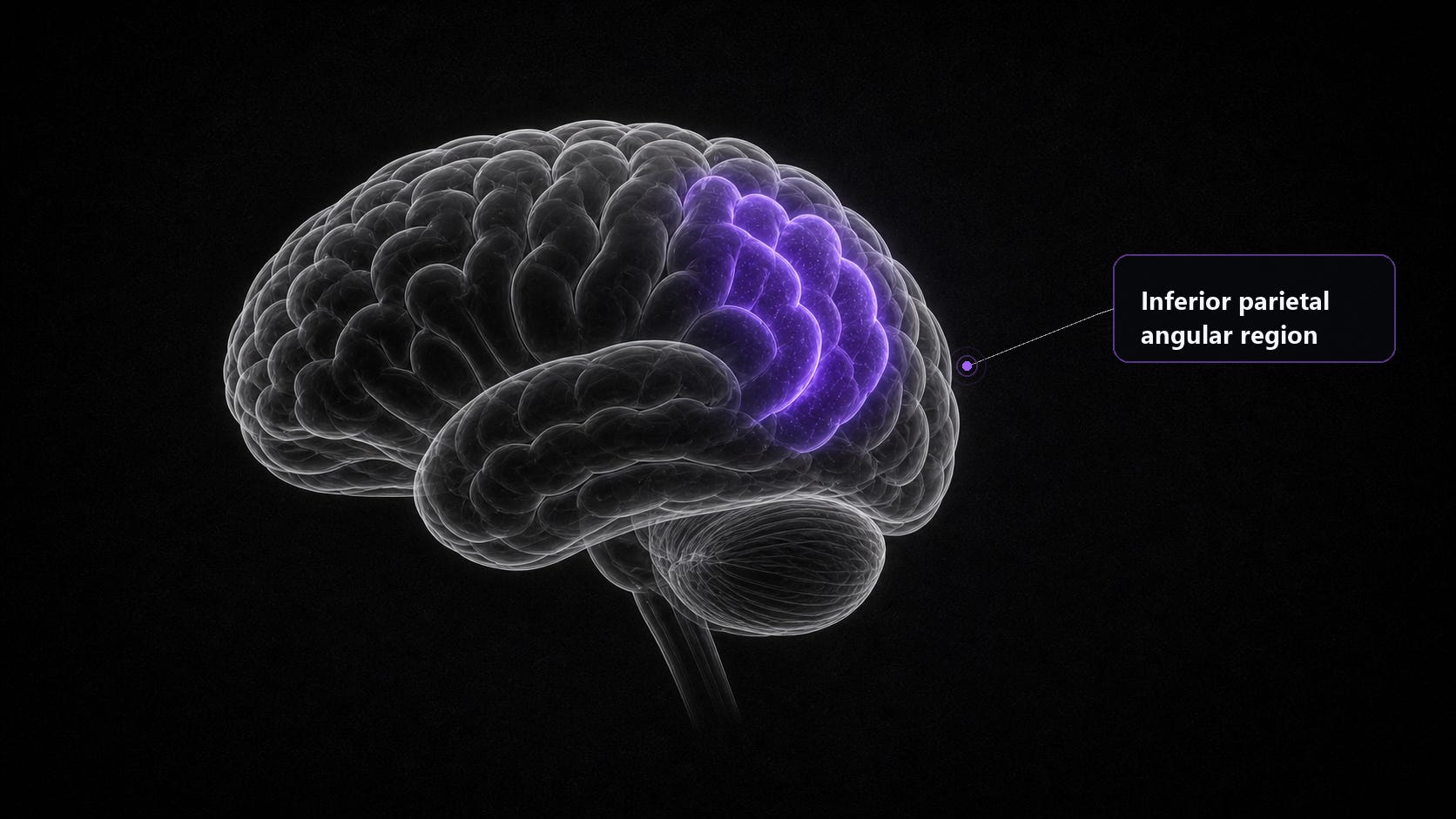
TRIBE v2 predicts that this closing drives the inferior parietal (angular) region, which integrates the whole piece into one take-home idea, the discourse-level synthesis that leaves you with a single point instead of a list.
A normal edit means reading your draft again and trusting your own judgment about where it lands.
This was the opposite. A model with no opinion about my writing predicted where a reader’s attention would actually go, second by second, and disagreed with me about my best parts.
It rated my opening near the bottom, my conclusion dead last, and a structural pivot I almost trimmed as the single strongest moment in the piece.
It didn’t make the article true, and it didn’t make it persuasive. It only showed me which sentences were doing the work and which ones I’d been protecting.
The strongest version of this piece turned out to be the one where I stopped arguing with the signal and let it delete the ending, including the one you would have read instead of this.
Sources:
Meta AI launch post — “Introducing TRIBE v2: A Predictive Foundation Model Trained to Understand How the Human Brain Processes Complex Stimuli,” published March 26, 2026. Meta says it is releasing the model, codebase, paper, and demo, and describes TRIBE v2 as predicting high-resolution fMRI brain activity for sights, sounds, and language. (Meta AI)
Meta AI Research publication page — “A foundation model of vision, audition, and language for in-silico neuroscience,” published March 26, 2026. It states TRIBE v2 is tri-modal — video, audio, and language — and was trained/evaluated on over 1,000 hours of fMRI across 720 subjects. (Meta AI)
arXiv paper — arXiv:2605.04326, submitted May 5, 2026, titled “A foundation model of vision, audition, and language for in-silico neuroscience,” by Stéphane d’Ascoli, Jérémy Rapin, Yohann Benchetrit, Teon Brooks, Katelyn Begany, Joséphine Raugel, Hubert Banville, and Jean-Rémi King. (arXiv)
TRIBE v2 GitHub repository —
facebookresearch/tribev2. The repo describes TRIBE v2 as a multimodal brain-encoding model for predicting fMRI responses to video, audio, and text, and includes quick-start inference code usingTribeModel.from_pretrained("facebook/tribev2"). (GitHub)TRIBE v2 Hugging Face model card —
facebook/tribev2. The model card lists the license as CC BY-NC 4.0 and describes the model as combining LLaMA 3.2, V-JEPA2, and Wav2Vec-BERT into a Transformer architecture mapping multimodal representations onto the cortical surface. (Hugging Face)Destrieux atlas background source — the Destrieux atlas refers to “Automatic parcellation of human cortical gyri and sulci using standard anatomical nomenclature,” NeuroImage, 2010, by Destrieux, Fischl, Dale, and Halgren. (nilearn.github.io)
Slowly coming back and excited to be reminded to read your posts again boss! 🫡🫡